Compliance & Responsible Research
Rethinking the consent template

Written by: Phil Hesketh
Published on:
We’ve been making some improvements to the way we create and utilise consent forms in Consent Kit.
Our initial research uncovered the following problems with creating consent forms:
People didn’t always know what to write or how much to disclose - creation was time consuming and confusing
They would often find someone who had created one recently and use their document instead
People were not confident that what they were using was legally compliant
Often the consent was not specific to the research being carried out
The reading age for consent was often higher than the national average

The process they followed looked something like this:
Ask the team for recent a consent form
Get a link to an existing consent form and make a copy
Edit the form to make it specific to the project that you are working on, asking questions or referring to articles online for guidance
Print off copies and take them with you
Have the participant sign the form
Scan the documents or take photos
Upload those photos to the project folder
Update a log manually in a spreadsheet
There is a lot of repetition in these steps from project to project. If I was ultra organised (which I’m not), I might set up reusable documents that I could copy and edit for each new project. Having said that, it still seems a little laborious having to repeat many of these steps unnecessarily each time.From an organisational level, my process still wouldn’t align with the rest of the researchers I work with. This makes life more complicated when dealing with things like information requests, deleting information or having to withdraw participants from research. The problem gets worse when people leave or switch teams as the knowledge of their process is often tacit and leaves with them.
Participants aren’t the only users
As we were designing how consent forms should work in Consent Kit, it became apparent that there were actually three key groups of people who would be affected. Research Ops or Administrators, Researchers and/or their teams and obviously; Participants.
Each of these groups have different needs we would have to meet.
ReOps need to know that any documents generated are consistent and compliant. They need to meet the requirements for the definition of informed consent without deviating from what has been agreed with an internal legal department.
Researchers need to know that they’re using the correct document which is accessible and easy to understand while saving them time and hassle in creating it.
Participants need to understand the contents and feel comfortable with it, enough to make a decision about if they want to take part in the research or not. English might not be a first language, so translation might be required or the document may need to be accessible by screen readers or other accessibility equipment.
Meta templates
The challenge with using static templates for consent is that there still needs to be a significant amount of rework done at the researcher level in order to make it “informed” consent. This doesn’t really address some of the problems we spoke about earlier; the creation of documents being time consuming and confusing, and opens the door again to inconsistencies across the wider organisation.
What if we used a system of templates that could be driven by the type of research the consent was being created for? Each component part of that template could be approved by your legal team and written by a content designer, to be reused automatically by the researcher each time at the point of need.
Very generally, research is carried out through a staple of methods for learning. For example; interviews, observations, usability testing, diary studies and workshops are some of the established methods for trying to understand human behaviour. This is by no means exhaustive, but rather to make a point that there is often repetition in the methods we select when we learn.
I think that this is interesting when thinking specifically about consent forms through a lens of templating.
Let’s break down a consent form into its component parts.
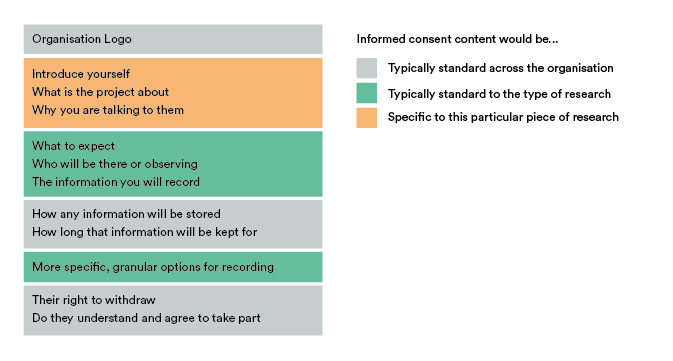
Let’s categorise these into three types: Standard across the organisation, standard to the type of research (event) and specific to a particular event.
Things like your logo, how you store information, how long for and their right to withdraw don’t need to change from form to form and are completely reusable. Additionally, your legal team might want to lock down certain aspects or phrasing in those parts, so actually preventing editing here is beneficial too.
Content concerning what to expect during the session, what type of information you record or even more specific granular options (like voice, audio, face being captured) could be reused if the Researcher can first state what kind of event they want the consent form for, like an interview or usability test for example.
Finally, things like introducing yourself and the project will always need to be created each time. Breaking it down even further, the structure of how that is worded could be reused if we also had prompts to guide the Researcher through completing that.
This approach allows us to reuse 80% of the content each time we create a form, while still being specific enough to give each participant enough information to make a decision. Applying event and user variables reduces the number of specifiable things down to three: What the research is about, its goals and why you want to talk to them.
The results so far
We’ve been running an Early Access program to develop these ideas in the wild. In that time, we’ve managed to dramatically reduce the amount of time it takes to pull a consent document together and get it out to participants. This, coupled with automatically handling the admin and keeping everything compliant has led to a saving of around 3 hours per event for researchers obtaining and managing informed consent. That’s time which can be spent extracting better insights, or doing more research.
In addition to the time saving - the entire consent process is also compliant from a GDPR perspective. You have a repeatable, scalable process which is not dependent on experience or prior expertise. That makes for a happy Research Ops team and Data Protection Officer.
Another benefit we’ve seen from early access has been Researchers are able to enable their wider team to take part. This approach allows us to scale the consent process consistently to people who have never done it before.
Here’s what some of our early access customers have said about it.
“No faffing with printing / carrying / scanning paperwork, and participant gets the automated email - overall makes research easier to manage. Setting up projects and forms is easy too. I’ve even been able to share a link with others on my team and be confident consent is covered and they’ll find it easy.”
“If it’s this easy for a complete beginner, I imagine actual user researchers would love it”
“I love it! So easy to set up and means you are covered from compliance perspective and not left with loads of sheets.”
What’s next
While most of the functionality stated above is already implemented, we’re continuing to develop it further. We want to give administrators more control over the structure of the document itself, while also giving them the ability to create their own event types and event content.
We’re building Consent Kit collaboratively with the research community. Say hello if you’d like to see for yourself or take part!


